本文基于《TLCL 快乐的 Linux 命令行》 ,计划每周给实验室同学普及一些linux常识。如果你希望深入学习,应当阅读原文。
如果你拥有丰富的经验,基础内容对你的帮助可能比较有限,但扩展内容应该能给你一些有益的启发。
基础内容: 重定向,echo;扩展内容:modern-unix
在上一篇《Tutorial:从零开始的Linux使用【1】》中,我们对linux的基础交互——shell与Terminal的使用,以及进行基础文件的操作进行了介绍。下面,我们将对linux中可能没那么频繁使用、但作为基础难以离开的命令行进行介绍。
在linux中,程序的运行结果输送到一个叫做标准输出的特殊文件(经常用 stdout 表示),而它们的状态信息则送到另一个 叫做标准错误输出的文件(stderr)。默认情况下,标准输出和标准错误输出都连接到屏幕,而不是保存到磁盘文件。除此之外,许多程序从一个叫做标准输入(stdin)的设备得到输入,默认情况下, 标准输入连接到键盘。而I/O 重定向允许我们更改输出地点和输入来源。一般来说,输入来自键盘,输出送到屏幕, 但是通过 I/O 重定向,我们可以做出改变。
关于重定向,下面的例子能较好地说明:
# 键盘输入,屏幕输出 ls -l /usr/bin # 将输出重定向到特定文件(替换模式) ls -l /usr/bin > ls-output.txt # 清空文件(将空白内容写入文件) > ls-output.txt # 将输出重定向到特定文件(增量模式,不替换原有文件) ls -l /usr/bin >> ls-output.txt # 将输出和错误报告重定向到特定文件 ## “2>&1” 代表重定向文件描述符2(标准错误输出)到文件描述符1(标准输出) ls -l /bin/usr > ls-output.txt 2>&1 ## bash 下也可以写成 ls -l /bin/usr &> ls-output.txt # 丢掉(不显示)错误报告 ls -l /bin/usr 2> /dev/null ## /dev/null是系统设备,叫做数字存储桶,它可以 接受输入,并且对输入不做任何处理 |
如果你对上面的内容无法理解,可以自己试一试,或者阅读原文 来深入学习,不过对大多数人来说,下面的代码就够使用了:
nohup <yourcode> &> nohup.out & ## 或者等效的写法 nohup <yourcode> >nohup.out 2>&1 & ## 它的意思是说把代码的输出和错误都输出到当前目录下的nohup.out文件中,并且后台运行(最后的“&”)。 ## 但如果你了解了重定向的写法和功能,就能在这基础上做你需要的修改。 |
很多时候,我们还希望把另一个代码的输出作为输入运行下一个代码,这里就需要用到管道线“|”,它在平时十分常用:
| zzza |
这样,你就对重定向有一定了解了,简单来说无非是用好“|”进行输入和用“>”进行输出。在实际linux使用中,二者还是相当实用的,例如:
history | grep cd nohup <yourcode> >nohup.out 2>&1 & |
原文在这一章加了一段很不错的解释,以资一笑:
当我被要求解释 Windows 与 Linux 之间的差异时,我经常拿玩具来作比喻。
Windows 就像一个游戏机。你去商店,买了一个包装在盒子里面的全新的游戏机。你把它带回家,打开盒子,开始玩游戏。精美的画面,动人的声音。玩了一段时间之后,你厌倦了它自带的游戏,所以你返回商店,又买了另一个游戏机。这个过程反复重复。 最后,你玩腻了游戏机自带的游戏,你回到商店,告诉售货员,“我想要一个这样的游戏!” 但售货员告诉你没有这样的游戏存在,因为它没有“市场需求”。然后你说,“但是我只 需要修改一下这个游戏!”,售货员又告诉你不能修改它。所有游戏都被封装在它们的 存储器中。到头来,你发现你的玩具只局限于别人为你规定好的游戏。
另一方面,Linux 就像一个全世界上最大的零件盒子。你打开它,发现它只是一个巨大的 部件集合。有许多钢支柱、螺钉、螺母、齿轮、滑轮、发动机和一些怎样来建造它的说明书。 然后你开始摆弄它。你建造了一个又一个样板模型。过了一会儿,你发现你要建造自己的模型。你不必返回商店,因为你已经拥有了你需要的一切。建造模型以你构想的形状为模板,搭建你想要的模型。
当然,选择哪一个玩具,是你的事情,那么你觉得哪个玩具更令人满意呢?
echo是shell内最基础的命令,现在来试试这行:
⋊> jiangyd@localhost ⋊> ~ echo "hello world" 19:39:07 hello world |
这个命令的作用相当简单明了。传递到 echo 命令的任一个参数都会在(屏幕上)显示出来。下面是一些例子:
# 使用通配符 ⋊> jiangyd@localhost ⋊> ~ echo 19:46:02 ⋊> jiangyd@localhost ⋊> ~ echo * 19:45:02 authorized_keys cache.db clash Country.mmdb Desktop Documents Downloads glados.yaml gromacs Music nohup.out Pictures Public stable-diffusion-webui Templates test Videos ⋊> jiangyd@localhost ⋊> ~ echo D* 19:46:23 Desktop Documents Downloads ⋊> jiangyd@localhost ⋊> ~ echo *s 19:47:06 authorized_keys Documents Downloads gromacs Pictures Templates Videos ⋊> jiangyd@localhost ⋊> ~ echo /usr/*/share 19:47:17 /usr/local/share ## 额外的,显示隐藏文件 ⋊> jiangyd@localhost ⋊> ~ echo .* 19:47:30 .bash_history .bash_logout .bash_profile .bashrc .cache .conda .condarc .config .cshrc .dbus .esd_auth .gaussian .gitconfig .history .history.7254921 .ICEauthority .keras .local .mozilla .npm .npmrc .nv .pki .python_history .ssh .viminfo .vscode-server .wget-hsts .Xauthority |
此外,echo可以做一些简单的计算。
[me@linuxbox ~]$ echo $((2 + 2)) 4 [me@linuxbox ~]$ echo $(($((5**2)) * 3)) 75 |
| 操作符 | 说明 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除(但是记住,因为展开只是支持整数除法,所以结果是整数。) |
| % | 取余,只是简单的意味着,“余数” |
| ** | 取幂 |
echo也可以进行一些列表展开:
[me@linuxbox ~]$ echo Front-{A,B,C}-Back
Front-A-Back Front-B-Back Front-C-Back
[me@linuxbox ~]$ echo {Z..A}
Z Y X W V U T S R Q P O N M L K J I H G F E D C B A
[me@linuxbox ~]$ echo a{A{1,2},B{3,4}}b
aA1b aA2b aB3b aB4b |
echo也可以展开一些参数
# 查看当前环境(包括参数)命令 printenv [jiangyd@localhost ~]$ printenv …… HOME=/home/jiangyd …… [jiangyd@localhost ~]$ echo $HOME /home/jiangyd |
要想精通echo,乃至写一些shell的脚本的话,下面的内容是有学习的必要的。对普通用户,下面的内容没有学习的必要,但有一定了解有助于你阅读一些脚本:
# 自动更正
[me@linuxbox ~]$ echo this is a test
this is a test
[me@linuxbox ~]$ echo The total is $100.00
The total is 00.00
## $1 的值替换为一个空字符串,因为 1 是没有定义的变量,因此为空
# 避免自动更正
## 双引号:shell 使用的特殊字符,都失去它们的特殊含义,被当作普通字符来看待
### $,\ , ` 仍然有效
[me@linuxbox ~]$ echo "this is a test"
this is a test
[me@linuxbox ~]$ echo "$USER $((2+2)) $(cal)"
me 4 February 2008
Su Mo Tu We Th Fr Sa
……
### 转义符号“\”可以避免符号被转义
[me@linuxbox ~]$ echo "The balance for user $USER is: \$5.00"
The balance for user me is: $5.00
### 特殊转义希望被翻译时(比如:\a代表响铃(”警告”-导致计算机嘟嘟响))需要加-e
[me@linuxbox ~]$ echo -e "Time's up\a"
### 双引号可以保护一些特定的格式,比如换行符
[me@linuxbox ~]$ echo $(cal)
February 2008 Su Mo Tu We Th Fr Sa 1 2 3 4 5 6 7 8 9 10 11 12 13 14
15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
[me@linuxbox ~]$ echo "$(cal)"
February 2008
....
## 单引号:不包含例外,符号一概失去特殊含义
[me@linuxbox ~]$ echo text ~/*.txt {a,b} $(echo foo) $((2+2)) $USER
text /home/me/ls-output.txt a b foo 4 me
[me@linuxbox ~]$ echo "text ~/*.txt {a,b} $(echo foo) $((2+2)) $USER"
text ~/*.txt {a,b} foo 4 me
[me@linuxbox ~]$ echo 'text ~/*.txt {a,b} $(echo foo) $((2+2)) $USER'
text ~/*.txt {a,b} $(echo foo) $((2+2)) $USER |
写到这里,你或许体会到linux命令行的学习并没有那么容易。所幸大部分unix命令都有了现代化的美化/优化版本,让你更好地使用linux。事实上,传统的linux命令在科研生产过程中已经没那么频繁地使用了,但是掌握他们对学习Linux还是有帮助的,这也是本文写作的目的所在。
此处只列举一些我平时常用的, 很多基础的unix命令都有优化版本,但不一定符合每个人的使用习惯。更多的可以在modern-unix的Github文档里找。
前面我们就推荐了tldr,这边再写一次,因为它实在太强大了:
⋊> jiangyd@localhost ⋊> ~ tldr cd 20:01:16 cd Change the current working directory. More information: https://manned.org/cd. - Go to the specified directory: cd path/to/directory - Go up to the parent of the current directory: cd .. - Go to the home directory of the current user: cd - Go to the home directory of the specified user: cd ~username - Go to the previously chosen directory: cd - - Go to the root directory: cd / |
它提供了美观、直观的介绍,相比help与man更易于实操,csdn上位替代
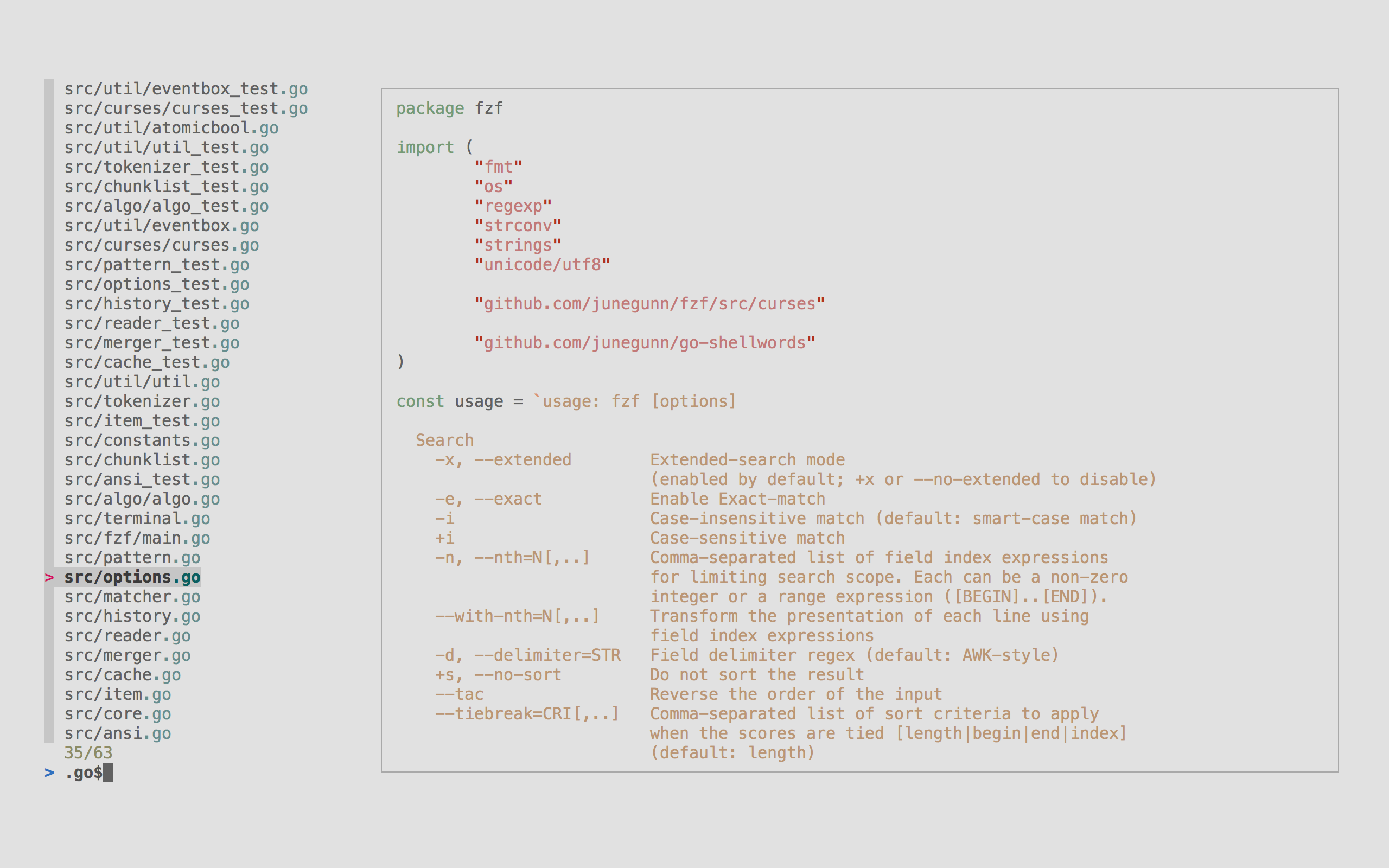 https://raw.githubusercontent.com/junegunn/i/master/fzf-preview.png
https://raw.githubusercontent.com/junegunn/i/master/fzf-preview.png
fzf是一个很有用的文本搜索工具,比如找history中的命令:
history | fzf |
虽然fish已经提供了很好的自动补全,但z让人可以更懒惰!连cd都可以优化!
z foo # cd into highest ranked directory matching foo z foo bar # cd into highest ranked directory matching foo and bar z foo / # cd into a subdirectory starting with foo z ~/foo # z also works like a regular cd command z foo/ # cd into relative path z .. # cd one level up z - # cd into previous directory zi foo # cd with interactive selection (using fzf) z foo<SPACE><TAB> # show interactive completions (zoxide v0.8.0+, bash 4.4+/fish/zsh only) |
duf(Disk Usage/Free Utility)[du]
 duf
duf
gtop(System monitoring dashboard for terminal)[top]
 gtop
gtop
基础内容:快捷键,权限,进程管理,shell环境,包管理器;扩展内容:anaconda,docker
读到这里,你应该已经对Linux的基础使用有了一定的理解,但是距离用好还有一定的距离。下面我们将介绍的内容能帮助你把Linux转化为实用的工具。
下面列举一些我觉得实用的快捷键,需压了解更多的可以阅读原文。
| 按键 | 行动 |
|---|---|
| Ctrl-a | 移动光标到行首。 |
| Ctrl-e | 移动光标到行尾。 |
| Ctrl-l | 清空屏幕,移动光标到左上角。clear 命令完成同样的工作 |
| Ctrl-k | 剪切从光标位置到行尾的文本。 |
| Ctrl-u | 剪切从光标位置到行首的文本。 |
| TAB | 自动补全 |
其余的很多快捷键,私以为都有更上位的取代,比如历史记录的搜索完全可以用fish shell下的上键搜索和基于fzf的“history | fzf”完成。因此,其他的就不做推荐了。
Linux 系统的多用户性能,不是最近的“创新”,而是一种深深地嵌入到了 Linux 操作系统的 设计中的特性。想想 Unix 系统的诞生环境,这一点就很好理解了。多年前,在个人电脑出现之前,计算机 都是大型、昂贵的、集中化的。例如一个典型的大学计算机系统,是由坐落在一座建筑中的一台 大型中央计算机和许多散布在校园各处的终端机组成,每个终端都连接到这台大型中央计算机。 这台计算机可以同时支持很多用户。
目前,服务器需要支持一整个实验室的运行,或者需要多人协作,因此权限的管理和文档的记录是相当重要的。这里重点关注权限的管理。
举个例子,当我们试图查看一个像/etc/shadow 那样的文件的时候,我们会遇到一个问题。
⋊> jiangyd@localhost ⋊> ~ file /etc/shadow 13:23:04 /etc/shadow: regular file, no read permission |
产生这种错误信息的原因是,作为一个普通用户,我们没有权限来读取这个文件。在 Unix 安全模型中,一个用户可能拥有文件和目录。当一个用户拥有一个文件或目录时, 用户对这个文件或目录的访问权限拥有控制权。用户反过来又属于一个由一个或多个 用户组成的用户组,用户组成员由文件和目录的所有者授予对文件和目录的访问权限。除了 对一个用户组授予权限之外,文件所有者可能会给所有的人授权,在 Unix 术语中,”所有的人“ 也被称作“整个世界”( world )。可以用 id 命令,来找到关于你自己身份的信息:
⋊> jiangyd@localhost ⋊> ~ id 13:23:12 uid=1000(jiangyd) gid=1013(Tanglab) groups=1013(Tanglab),0(root),970(docker) |
这些用户、用户组的信息,被系统以文本文档的形式保存。用户帐户定义在 /etc/passwd 文件里面,用户组定义在 /etc/group 文件里面。这些文本还保存了大量系统用户的信息。
而每一个文件,对用户和用户组都有着明确的权限规定。比如:
⋊> jiangyd@localhost ⋊> ~ ls -al /etc/passwd 13:23:54 -rw-r--r-- 1 root root 3510 Nov 9 14:55 /etc/passwd # 第一列代表权限,后面表示拥有者和所属用户组都是root |
| 属性 | 文件 | 目录 |
|---|---|---|
| r | 允许打开并读取文件内容。 | 允许列出目录中的内容,前提是目录必须设置了可执行属性(x)。 |
| w | 允许写入文件内容或截断文件。但是不允许对文件进行重命名或删除,重命名或删除是由目录的属性决定的。 | 允许在目录下新建、删除或重命名文件,前提是目录必须设置了可执行属性(x)。 |
| x | 允许将文件作为程序来执行,使用脚本语言编写的程序必须设置为可读才能被执行。 | 允许进入目录,例如:cd directory 。 |
现在,我们就明白了为何一些权限无法访问,下面是一些例子:
| 文件属性 | 含义 |
|---|---|
| -rwx—— | 一个普通文件,对文件所有者来说可读、可写、可执行。其他人无法访问。 |
| -rw——- | 一个普通文件,对文件所有者来说可读可写。其他人无法访问。 |
| -rw-r–r– | 一个普通文件,对文件所有者来说可读可写,文件所有者的组成员可以读该文件,其他所有人都可以读该文件。 |
| -rwxr-xr-x | 一个普通文件,对文件所有者来说可读、可写、可执行。也可以被其他的所有人读取和执行。 |
| -rw-rw—- | 一个普通文件,对文件所有者以及文件所有者的组成员来说可读可写。 |
| lrwxrwxrwx | 一个符号链接,符号链接的权限都是虚拟的,真实的权限应该以符号链接指向的文件为准。 |
| drwxrwx— | 一个目录,文件所有者以及文件所有者的组成员可以访问该目录,并且可以在该目录下新建、重命名、删除文件。 |
| drwxr-x— | 一个目录,文件所有者可以访问该目录,并且可以在该目录下新建、重命名、删除文件,文件所有者的组成员可以访问该目录,但是不能新建、重命名、删除文件。 |
如果想要更改一个文件的权限(注意只有文件的所有者或者超级用户才能更改文件或目录的权限),要用chmod命令。chmod 命令支持两种不同的方法来改变文件模式:八进制数字表示法或 符号表示法。首先我们讨论一下八进制数字表示法,二者的对应关系如下表:
| Octal | Binary | File Mode |
|---|---|---|
| 0 | 000 | — |
| 1 | 001 | –x |
| 2 | 010 | -w- |
| 3 | 011 | -wx |
| 4 | 100 | r– |
| 5 | 101 | r-x |
| 6 | 110 | rw- |
| 7 | 111 | rwx |
读了这个表,相信你对于所谓的“777”“755”权限便不再陌生了:它们只是说明了文件所有者、文件所属组成员和其他人拥有的权限,具体权限的内容对应上表。如果这些数字不够直观,你也可以使用更直观的字母表示法:
| u | “user”的简写,意思是文件或目录的所有者。 |
|---|---|
| g | 用户组。 |
| o | “others”的简写,意思是其他所有的人。 |
| a | “all”的简写,是”u”, “g”和“o”三者的联合 |
| u+x | 为文件所有者添加可执行权限。 |
|---|---|
| u-x | 删除文件所有者的可执行权限。 |
| +x | 为文件所有者,用户组,和其他所有人添加可执行权限。 等价于 a+x。 |
| o-rw | 除了文件所有者和用户组,删除其他人的读权限和写权限。 |
| go=rw | 给文件所属的组和文件所属者/组以外的人读写权限。如果文件所属组或其他人已经拥有执行的权限,执行权限将被移除。 |
| u+x,go=rw | 给文件拥有者执行权限并给组和其他人读和执行的权限。多种设定可以用逗号分开 |
如果你还是无法理解,也没有关系,权限管理一般是管理员的工作,你只需要能看懂“ls -al”命令提示的权限,并且采取对应权限的操作就行了。
最后,我们将介绍两个特殊的命令,sudo和su。su 命令允许你假定为另一个用户的身份,以这个用户的 ID 启动一个新的 shell 会话,或者是以这个用户的身份来发布一个命令。sudo 命令允许一个管理员 设置一个叫做 /etc/sudoers 的配置文件,并且定义了一些具体命令,允许变身用户 执行这些命令。这可以防止直接使用root用户带来的不安全性。不过这两个命令一般都需要管理员才会用到,因此当你遇到需要使用相关命令的时候,直接向管理员求助吧。
在需要更改拥有者和用户组的时候,还会用到chown和chgrp命令,一般这也会由管理员进行,不多介绍了。进一步的,还有useradd(区别于adduser),groupadd等命令,感兴趣的可以自行查阅文档。
有时候,计算机变得呆滞,运行缓慢,或者一个应用程序停止响应。在这一章中,我们将看一些 可用的命令行工具,这些工具帮助我们查看程序的执行状态,以及怎样终止行为不当的进程。在多人协作的服务器上,关注别人的进程也能防止过多进程造成冲突导致服务器奔溃。
当系统启动的时候,内核先把一些它自己的活动初始化为进程,然后运行一个叫做 init 的程序。init, 依次地,再运行一系列的称为 init 脚本的 shell 脚本(位于 /etc ),它们可以启动所有的系统服务。 其中许多系统服务以守护进程(daemon)的形式实现,守护进程仅在后台运行,没有任何用户接口(User Interface)。 即使我们没有登录系统,系统也在执行一些例行事务。
内核维护每个进程的信息,以此来保持事情有序。例如,系统分配给每个进程一个数字,这个数字叫做 进程(process) ID 或 PID。PID 号按升序分配,init 进程的 PID 总是1。内核也对分配给每个进程的内存和就绪状态进行跟踪以便继续执行这个进程。 像文件一样,进程也有所有者和用户 ID,有效用户 ID,等等。
查看进程,最常使用地命令(有几个命令)是 ps(process status)。ps 程序有许多选项,它最简单地使用形式是这样的:
[me@linuxbox ~]$ ps PID TTY TIME CMD 5198 pts/1 00:00:00 bash 10129 pts/1 00:00:00 ps |
如果给 ps 命令加上选项,我们可以得到更多关于系统运行状态的信息:
- List all running processes: ps aux - List all running processes including the full command string: ps auxww - Search for a process that matches a string: ps aux | grep string - List all processes of the current user in extra full format: ps --user $(id -u) -F - List all processes of the current user as a tree: ps --user $(id -u) f - Get the parent PID of a process: ps -o ppid= -p pid - Sort processes by memory consumption: ps --sort size |
当然,进一步地,也可以用modern-unix中的procs来代替ps,这就取决于每个人的使用习惯了。当然,你也可以用top来动态查看进程,它也有更美观的版本gtop 。这些命令都可以利用管道线,和fzf、grep进行联用,试试下面的命令吧:
ps aux | grep systemd ps aux | fzf |
在linux中最常用的杀死进程的方式应当是使用Ctrl-c。通过这个技巧,许多(但不是全部)命令行程序可以被中断。但很多时候,我们只是希望进行其他操作,不希望未停止的进程阻止我们输入,那我们可以把它放到后台:
<yourcommand> & |
不过,更多时候,我们想直接“杀死”程序。kill 命令被用来“杀死”程序。这样我们就可以终止需要杀死的程序。例如:
[me@linuxbox ~]$ xlogo & [1] 28401 [me@linuxbox ~]$ kill 28401 [1]+ Terminated xlogo |
虽然这个命令看上去很直白, 但是它的含义不止于此。这个 kill 命令不是真的“杀死”程序,而是给程序 发送信号。信号是操作系统与程序之间进行通信时所采用的几种方式中的一种。 Ctrl-c 和 Ctrl-z 就是信号的实际例子。当终端接受了其中一个按键组合后,它会给在前端运行的程序发送一个信号。在使用 Ctrl-c 的情况下,会发送一个叫做 INT(Interrupt ,中断)的信号;当使用 Ctrl-z 时,则发送一个叫做 TSTP(Terminal Stop ,终端停止)的信号。程序,相应地,监听信号的到来,当程序 接到信号之后,则做出响应。一个程序能够监听和响应信号这件事允许一个程序做些事情, 比如,当程序接到一个终止信号时,它可以保存所做的工作。下面是kill发送信号的含义:
| 编号 | 名字 | 含义 |
|---|---|---|
| 1 | HUP | 挂起(Hangup)。名字来源于很久以前,那时候终端机通过电话线和调制解调器连接到 远端的计算机。这个信号被用来告诉程序,控制的终端机已经“挂断”。 通过关闭一个终端会话,可以展示这个信号的作用。在当前终端运行的前台程序将会收到这个信号并终止。许多守护进程也使用这个信号,来重新初始化。这意味着,当一个守护进程收到这个信号后, 这个进程会重新启动,并且重新读取它的配置文件。Apache 网络服务器守护进程就是一个例子。 |
| 2 | INT | 中断。实现和 Ctrl-c 一样的功能,由终端发送。通常,它会终止一个程序。 |
| 9 | KILL | 杀死。这个信号很特别。尽管程序可能会选择不同的方式来处理发送给它的 信号,其中也包含忽略信号,但是 KILL 信号从不被发送到目标程序。而是内核立即终止 这个进程。当一个进程以这种方式终止的时候,它没有机会去做些“清理”工作,或者是保存工作。 因为这个原因,把 KILL 信号看作最后一招,当其它终止信号失败后,再使用它。 |
| 15 | TERM | 终止。这是 kill 命令发送的默认信号。如果程序仍然“活着”,可以接受信号,那么 这个它会终止。 |
| 18 | CONT | 继续。在一个停止信号后,这个信号会恢复进程的运行。 |
| 19 | STOP | 停止。这个信号导致进程停止运行,而不是终止。像 KILL 信号,它不被 发送到目标进程,因此它不能被忽略。 |
进程,和文件一样,拥有所有者,所以为了能够通过 kill 命令来给进程发送信号, 你必须是进程的所有者(或者是超级用户)。
此外,通过 killall 命令,给匹配特定程序或用户名的多个进程发送信号。下面是 killall 命令的语法形式:
killall [-u user] [-signal] name... |
例如:
[me@linuxbox ~]$ xlogo & [1] 18801 [me@linuxbox ~]$ xlogo & [2] 18802 [me@linuxbox ~]$ killall xlogo [1]- Terminated xlogo [2]+ Terminated xlogo |
shell 在 shell 会话中保存着大量信息。这些信息被称为 (shell 的) 环境。 程序获取环境中的数据(即环境变量)来了解本机的配置。虽然大多数程序用配置文件来存储程序设置, 一些程序会根据环境变量来调整他们的行为。知道了这些,我们就可以用环境变量来自定制 shell 体验。
常用的方式有两种:
set | less(也可以用fzf) printenv | less(也可以用fzf) |
printenv 命令也能够列出特定变量的值:
[me@linuxbox ~]$ printenv USER me |
别名无法通过使用 set 或 printenv 来查看。用不带参数的 alias 来查看别名:
⋊> jiangyd@localhost ⋊> ~ bash 14:29:23 [jiangyd@localhost ~]$ alias alias egrep='egrep --color=auto' alias fgrep='fgrep --color=auto' alias fzf='/var/lib/snapd/snap/bin/fzf-carroarmato0.fzf' alias grep='grep --color=auto' alias gv='/smb/jiangyd//gv/gview.sh' alias l.='ls -d .* --color=auto' alias ll='ls -l --color=auto' alias ls='ls --color=auto' alias sl='/smb/jiangyd//g16/tests/searchlog.csh' alias vi='vim' alias xzegrep='xzegrep --color=auto' alias xzfgrep='xzfgrep --color=auto' alias xzgrep='xzgrep --color=auto' alias zegrep='zegrep --color=auto' alias zfgrep='zfgrep --color=auto' alias zgrep='zgrep --color=auto' |
下面是一些常见的环境变量:
| 变量 | 内容 |
|---|---|
| DISPLAY | 如果你正在运行图形界面环境,那么这个变量就是你显示器的名字。通常,它是 “:0”, 意思是由 X 产生的第一个显示器。 |
| EDITOR | 文本编辑器的名字。 |
| SHELL | shell 程序的名字。 |
| HOME | 用户家目录。 |
| LANG | 定义了字符集以及语言编码方式。 |
| OLD_PWD | 先前的工作目录。 |
| PAGER | 页输出程序的名字。这经常设置为/usr/bin/less。 |
| PATH | 由冒号分开的目录列表,当你输入可执行程序名后,会搜索这个目录列表。 |
| PS1 | Prompt String 1. 这个定义了你的 shell 提示符的内容。随后我们可以看到,这个变量 内容可以全面地定制。 |
| PWD | 当前工作目录。 |
| TERM | 终端类型名。类 Unix 的系统支持许多终端协议;这个变量设置你的终端仿真器所用的协议。 |
| TZ | 指定你所在的时区。大多数类 Unix 的系统按照协调时间时 (UTC) 来维护计算机内部的时钟 ,然后应用一个由这个变量指定的偏差来显示本地时间。 |
| USER | 你的用户名 |
当我们登录系统后, bash 程序启动,并且会读取一系列称为启动文件的配置脚本, 这些文件定义了默认的可供所有用户共享的 shell 环境。然后是读取更于当前用户自己home目录中 的启动文件,这些启动文件定义了用户个人的 shell 环境。确切的启动顺序依赖于要运行的 shell 会话 类型。有两种 shell 会话类型:一个是登录 shell 会话,另一个是非登录 shell 会话。登录 shell 会话会在其中提示用户输入用户名和密码;例如,我们启动一个虚拟控制台会话。 非登录 shell 会话通常当我们在 GUI 下启动终端会话时出现。
登录shell会话的启动文件:
| 文件 | 内容 |
|---|---|
| /etc/profile | 应用于所有用户的全局配置脚本。 |
| ~/.bash_profile | 用户个人的启动文件。可以用来扩展或重写全局配置脚本中的设置。 |
| ~/.bash_login | 如果文件 ~/.bash_profile 没有找到,bash 会尝试读取这个脚本。 |
| ~/.profile | 如果文件 ~/.bash_profile 或文件 ~/.bash_login 都没有找到,bash 会试图读取这个文件。 这是基于 Debian 发行版的默认设置,比方说 Ubuntu。 |
非登录 shell 会话会读取以下启动文件:
| 文件 | 内容 |
|---|---|
| /etc/bash.bashrc | 应用于所有用户的全局配置文件。 |
| ~/.bashrc | 用户个人的启动文件。可以用来扩展或重写全局配置脚本中的设置。 |
对大多数用户而言,全局配置是由管理员修改的,只需要修改个人配置就行了。
我们看一下典型的 .bash_profile 文件(来自于 CentOS 4 系统),它看起来像这样
# .bash_profile # Get the aliases and functions if [ -f ~/.bashrc ]; then . ~/.bashrc fi # User specific environment and startup programs PATH=$PATH:$HOME/bin export PATH |
以”#”开头的行是注释,shell 不会读取它们。它们在那里是为了方便人们阅读。
是否曾经对 shell 怎样知道在哪里找到我们在命令行中输入的命令感到迷惑?例如,当我们输入 ls 后, shell 不会查找整个计算机系统来找到 /bin/ls(ls 命令的全路径名),相反,它查找一个目录列表,这个列表就包含在 PATH 变量中。
PATH 变量经常(但不总是,依赖于发行版)在 /etc/profile 启动文件中设置,通过这些代码:
PATH=$PATH:$HOME/bin # 修改 PATH 变量,添加目录 $HOME/bin 到目录列表的末尾。 # 注意:很多发行版默认地提供了这个 PATH 设置。一些基于 Debian 的发行版,例如 Ubuntu,在登录 的时候,会检测目录 ~/bin 是否存在,若找到目录则把它动态地加到 PATH 变量中。 |
最后,export PATH命令告诉 shell 让这个 shell 的子进程可以使用 PATH 变量的内容。
很多时候,安装新的软件都需要添加环境配置,这时就需要用文本编辑器编辑shell配置。
在使用文本编辑器修改这个shell配置后,还需要将其激活,一般需要关闭终端会话,再重新启动一个新的会话, 因为 .bashrc 文件只是在刚开始启动终端会话时读取。然而,我们可以强迫 bash 重新读取修改过的文件,例如下面的命令:
source .bashrc |
现在,你可以通过修改shell配置完成一些很cool的事了,比如说为你常用的命令设置alias别名——这样每次登录后,你就可以用缩写来使用他们了。
但是,修改环境是一件枯燥的重复性劳动,因此在实际生产过程中,我们更希望用简便的拌饭来管理环境。在扩展内容中,将介绍几种常用的环境管理方法。
软件包管理是指系统中一种安装和维护软件的方法。今天,通过 Linux 发行版中安装的软件包,已能满足许多人的需求。这不同于早期的 Linux,人们需要下载和编译源码来安装软件。编译源码没有任何问题,事实上,拥有对源码的访问权限是 Linux 的伟大奇迹。它赋予我们提高系统性能的能力。只是若有一个预先编译好的软件包处理起来要相对容易快速些。包管理器让软件的查询、安装和配置变得轻松,而命令行操作则简化了安装过程。
| 包管理系统 | 发行版 (部分列表) |
|---|---|
| Debian Style (.deb) | Debian, Ubuntu, Xandros, Linspire |
| Red Hat Style (.rpm) | Fedora, CentOS, Red Hat Enterprise Linux, OpenSUSE, Mandriva, PCLinuxOS |
在包管理系统中软件的基本单元是包文件。包文件是一个构成软件包的文件压缩集合。一个软件包可能由大量程序以及支持这些程序的数据文件组成。除了安装文件之外,软件包文件也包括这个包的元数据,也就是对软件包的说明。另外,许多软件包还包括预安装和安装后脚本,这些脚本用来在软件安装之前和之后执行配置任务。
软件包文件是由软件包维护者创建的,他通常是(但不总是)一名软件发行商的雇员。软件维护者从上游提供商(程序作者)那里得到软件源码,然后编译源码,创建软件包元数据以及所需要的安装脚本。通常,软件包维护者要把所做的修改应用到最初的源码当中,来提高此软件与 Linux 发行版其它部分的融合性。
虽然某些软件项目选择执行他们自己的打包和发布策略,但是现在大多数软件包是由发行商和感兴趣的第三方创建的。系统发行版的用户可以在一个中心包仓库中得到这些软件包,包仓库可能包含了成千上万个软件包,每一个软件包都是专门为这个系统发行版建立和维护的。
因软件开发生命周期不同阶段的需要,一个系统发行版可能维护着几个不同的包仓库。例如,通常会有一个”测试”包仓库,其中包含比较新的软件包,它们想要勇敢的用户来使用,在这些软件包正式发布之前,让用户查找错误。系统发行版经常会有一个”开发版”包仓库,这个库中保存着注定要包含到下一个主要版本中的半成品软件包。
一个系统发行版可能也会拥有相关第三方的包仓库。这些库需要支持一些因法律原因,比如说专利或者是 DRM 反规避问题,而不能被包含到发行版中的软件。可能最著名的案例就是对加密DVD的播放支持,在美国这是不合法的。第三方包仓库在一些软件专利和反规避法案不 生效的国家中设立并分发资源。这些库通常完全地独立于它们所支持的包仓库,要想使用它们,你必须了解它们,手动地把它们包含到软件包管理系统的配置文件中。
程序很少独立工作;他们需要依靠其他程序的组件来完成他们的工作。程序所共有的活动,如输入/输出,就是由一个被多个程序调用的子例程处理的。这些子例程存储在动态链接库中。动态链接库为多个程序提供基本服务。如果一个软件包需要一些共享的资源,如一个动态链接库,它就被称作有一个依赖。现代的软件包管理系统都提供了一些依赖项解析方法,以确保安装软件包时,其所有的依赖也被安装。
软件包管理系统通常由两种工具类型组成:底层工具用来处理这些任务,比方说安装和删除软件包文件,和上层工具,完成元数据搜索和依赖解析。
| 发行版 | 底层工具 | 上层工具 |
|---|---|---|
| Debian-Style | dpkg | apt-get, aptitude |
| Fedora, Red Hat Enterprise Linux, CentOS | rpm | yum |
下面给出一些常用的例子,不过可能需要超级用户权限:
| 风格 | 命令 |
|---|---|
| Debian | apt-get update; apt-cache search search_string |
| Red Hat | yum search search_string |
| 风格 | 命令 |
|---|---|
| Debian | apt-get update; apt-get install package_name |
| Red Hat | yum install package_name |
| 风格 | 命令 |
|---|---|
| Debian | apt-get remove package_name |
| Red Hat | yum erase package_name |
| 风格 | 命令 |
|---|---|
| Debian | apt-get update; apt-get upgrade |
| Red Hat | yum update |
| 风格 | 命令 |
|---|---|
| Debian | dpkg –install package_file |
| Red Hat | rpm -i package_file |
因此,Linux上安装软件和设备是更加容易的。
Linux软件生态系统是基于开放源代码理念。如果一个程序开发人员发布了一款产品的源码,那么与系统发行版相关联的开发人员可能就会把这款产品打包,并把它包含在他们的包仓库中。这种方法保证了这款产品能很好地与系统发行版整合在一起,同时为用户“一站式采购”软件提供了方便,从而用户不必去搜索每个产品的网站。
设备驱动差不多也以同样的方式来处理,但它们不是系统发行版包仓库中单独的项目,它们本身是 Linux 系统内核的一部分。一般来说,在 Linux 当中没有一个类似于“驱动盘”的东西。 Linux 内核要么支持一个设备,要不就不支持。Linux 内核支持很多设备,事实上,Linux 支持的设备数目多于 Windows 所支持的。当然,万一你需要的特定设备不被 Linux 支持,也于事无补。
最后,由于linux系统一般默认集成的源是国外的源。源是 Linux 系统中的一个文件,可以说是 Linux 的灵魂,一个 Linux 配置的源文件决定了 Linux 系统可以获取哪些资源,获取哪些文件,源文件损坏意味着 Linux 系统无法下载 / 更新等。使用国外的源下载 / 更新十分缓慢,并且由于速度慢,可能会导致下载错误,中途停止等状况发生。因此,在使用包管理器前,一般要先换用国内源。具体可以参考Github上的换源脚本。
因为包管理器具有简化部署工作、自动完成配置、易于管理版本等优点,在实际生产中被我频繁地使用。类似于MacOS上的brew, Windows上可以在powershell中使用choco 。
事实上,每种语言或者框架都有配套的包管理系统,本质上他们的作用都一样:环境隔离与版本控制。python的pip和conda,nodejs的npm,也都是包管理器,下面就对目前比较常用的conda进行介绍。
Conda用Python语言开发,但能管理其他编程语言的项目,包括多语言项目。
在实际生产过程中,往往需要使用不同版本的python及其软件包,可以通过conda激活不同的虚拟环境,来应对不同的生产需求。
比较常用的包括:
#首先打开命令行(最好用管理员模式打开) 。 #输入 conda --version 显示conda版本号。 #输入conda upgrade --all 把所有工具包进行升级 #输入conda activate 环境名 切换到指定的环境。如果未指定环境名,则切换到默认的base环境。 #输入conda activate /path/to/environment-dir 切换到指定路径作为环境。 #输入conda list 列出当前环境的所有已经安装的包 #输入conda env list 列出所有的环境 #输入conda remove --name ENVNAME --all 删除一个环境 #输入conda create -n 环境名 python=3 创建一个指定名称的虚拟环境并指定python版本为3,conda会自动找3中最新的版本下载。 #输入conda install 包名,安装指定的包 #输入conda remove 包名 ,卸载指定的包 #输入conda remove -n 环境名 --all // 删除指定环境及下所有包 #输入conda update 包名 更新指定包 #输入conda create --clone ENVNAME --name NEWENV 克隆一个环境 #输入conda env export > environment.yaml或输入conda env export --file python36_20190106.yaml 导出当前环境的包信息 #输入conda env update -n EnvName --file ConfigureName.yaml用配置文件升级当前环境 #输入conda env create -f environment.yaml 用配置文件创建新的虚拟环境 #克隆一个环境:首先找到要复制的环境的路径 conda info --env 然后利用克隆命令复制到你要配的账户:conda create -n NewEnvName --clone <path> #升级一个包(以tensorflow为例): #在Anaconda prompt下,运行anaconda search -t conda tensorflow #选择符合自己系统的版本按照提示运行以下命令 anaconda show USER/PACKAGE //USER/PACKAGE是上一步查出来的Name #按照上步安装提示执行conda install --channel https://conda.anaconda.org/anaconda tensorflow #输入y,确认要下载安装的包 # 设置国内镜像源 # 安装多个packages时,conda下载的速度经常很慢。清华TUNA镜像源有Anaconda仓库的镜像,将其加入conda的配置即可: #conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/ #conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ #conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ #conda config --set show_channel_urls yes # 恢复默认镜像 # conda config --remove-key channels |
2013年发布至今, Docker 一直广受瞩目,被认为可能会改变软件行业。今天可以说,Docker也许是环境隔离和版本控制的终极方案——阮老师在他的教程里对此进行了详细的介绍,本文只简单介绍一些要点。
软件开发最大的麻烦事之一,就是环境配置。用户计算机的环境都不相同,你怎么知道自家的软件,能在那些机器跑起来?
用户必须保证两件事:操作系统的设置,各种库和组件的安装。只有它们都正确,软件才能运行。举例来说,安装一个 Python 应用,计算机必须有 Python 引擎,还必须有各种依赖,可能还要配置环境变量。
如果某些老旧的模块与当前环境不兼容,那就麻烦了。开发者常常会说:”它在我的机器可以跑了”(It works on my machine),言下之意就是,其他机器很可能跑不了。
环境配置如此麻烦,换一台机器,就要重来一次,旷日费时。很多人想到,能不能从根本上解决问题,软件可以带环境安装?也就是说,安装的时候,把原始环境一模一样地复制过来。
虚拟机(virtual machine)就是带环境安装的一种解决方案。它可以在一种操作系统里面运行另一种操作系统,比如在 Windows 系统里面运行 Linux 系统。应用程序对此毫无感知,因为虚拟机看上去跟真实系统一模一样,而对于底层系统来说,虚拟机就是一个普通文件,不需要了就删掉,对其他部分毫无影响。
虽然用户可以通过虚拟机还原软件的原始环境。但是,这个方案有几个缺点:
资源占用多
冗余步骤多
启动慢
由于虚拟机存在这些缺点,Linux 发展出了另一种虚拟化技术:Linux 容器(Linux Containers,缩写为 LXC)。Linux 容器不是模拟一个完整的操作系统,而是对进程进行隔离。它具有启动快、资源占用少、体积小的优点。总之,容器有点像轻量级的虚拟机,能够提供虚拟化的环境,但是成本开销小得多。
Docker 属于 Linux 容器的一种封装,提供简单易用的容器使用接口。它是目前最流行的 Linux 容器解决方案。
Docker 将应用程序与该程序的依赖,打包在一个文件里面。运行这个文件,就会生成一个虚拟容器。程序在这个虚拟容器里运行,就好像在真实的物理机上运行一样。有了 Docker,就不用担心环境问题。
总体来说,Docker 的接口相当简单,用户可以方便地创建和使用容器,把自己的应用放入容器。容器还可以进行版本管理、复制、分享、修改,就像管理普通的代码一样。
有了docker,就可以做各方面的工作了。教程事例可以看菜鸟教程,而常用的docker包可以上官网搜索。现在你可以用docker安装Ubuntu, CentOS, python……也可以把你的软件打包成docker部署在其它环境里了。还在为没有管理员权限发愁?用docker创建一个独属于你的子系统吧!